 我问答网
我问答网上周五下午,我们团队为一个数据仓库查询的性能瓶颈吵得不可开交。一个刚来的实习生怯生生地问:’这不就是个更大的Excel吗?’——整个会议室突然安静了三秒,然后爆笑。说实话,这问题还真不是笑话。
大多数人第一次接触大数据这个词,脑子里蹦出来的画面,就是海量的表格,无限的滚动条。但大数据这玩意儿,真不是’更大的数据’那么简单。不然我们这些搞数据的还混什么饭吃,对吧?
✅ 先看看,啥才叫’大数据’
业内常说的4V——Volume(量大)、Velocity(速度快)、Variety(种类杂)、Value(价值密度低)——虽然有点学院派,但确实一针见血。拿普通数据对比:你平时的银行流水,几十笔交易,一个CSV文件撑死几KB,Excel打开秒开,这叫普通数据。但如果你要分析整个城市所有银行、所有ATM、所有POS机每一秒的交易流水——一天就是几十亿条记录,还要实时监测欺诈行为——得,这就是大数据了。
我早期做的一个电商用户行为分析项目,日志文件每天新增十几个TB。什么概念?就是如果你用普通笔记本打开那个文件,硬盘灯闪到你怀疑人生,然后可能会直接死给你看。这就是Volume。

但量大只是敲门砖。速度才真要命。流量高峰时,用户点击、下单、支付,这些数据是瀑布一样涌进来的,你不可能等它攒成几个G再慢慢分析——欺诈检测、实时推荐,都要在毫秒级完成。这就像你一边在高压水枪下喝水,一边还要数清楚喝了几口水,中间有没有怪味。这种流式数据的要求,传统的关系型数据库根本顶不住。
至于种类杂……头疼。你以为数据就是整齐的行列?图样图森破。图片、视频、社交文本、GPS轨迹、搜索关键词、甚至天气数据,这些非结构化的东西才是大数据的深渊。我记得有一次要融合用户评论情感分析和购买转化数据,光是把微博上的颜文字和表情符号转成可分析的特征,就让我差点砸键盘——🤬这个表情到底算负面还是超级负面?最后还是手动标注了五百条数据才搞定。
❗ 普通数据能处理的,大数据怎么就不行了?
简单说,普通数据是’小数据思维’,我们习惯抽样本、做假设、然后验证。但大数据来了,可以做到’全量数据’,也就是把相关的一切都记录下来,直接让数据自己说话。听起来很美对吧?但背后的工程技术是地狱级难度。
单机处理不了怎么办?分布式存储、分布式计算。于是有了Hadoop、Spark、Flink这些框架。存储方面,不再是一台数据库服务器,而是数百个节点组成的集群。计算的时候,把任务拆分成无数个小块,在每个节点上并行跑,最后汇总结果。这就像你一个人盖房子要一年,雇一百个工人协调好,可能一周就搞定——但工头(调度器)必须极度聪明,不然工人会打架。
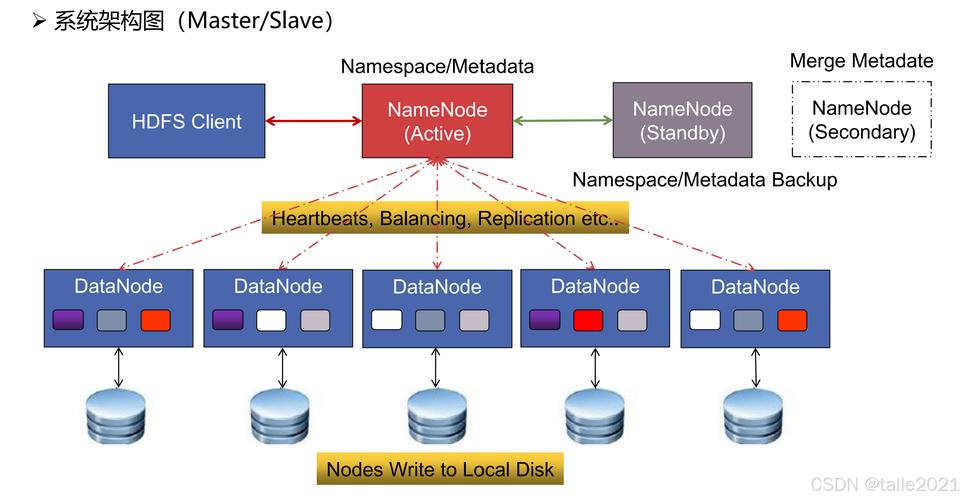
还有数据一致性、故障恢复……任何一个节点随时可能挂掉,系统不能丢数据、不能算错结果。这背后的理论可以追溯到Google的三大论文,后来催生了整个开源生态。不过说实话,现在云服务这么成熟,很多公司直接用AWS的EMR或者阿里云的MaxCompute,省去了搭集群的苦活。但懂原理的人,解决问题时还是特别快——这点我深有体会,之前一个Join操作倾斜严重,不懂MapReduce底层的话,调参调到天黑都没用。
💡 那大数据到底改变了什么?
粗暴点讲,它让我们从’事后诸葛亮’变成了’实时上帝视角’。以前的商业决策靠季度报告、年度总结,现在你打开淘宝首页,那个推荐栏是秒级更新的,它知道你刚才在搜什么,甚至能猜出你下一步想买什么——虽然有时猜得离谱,比如我给猫买过猫粮后,它疯狂给我推猫厕所,我又没猫砂盆恐惧症。
另一个震撼我的应用,是交通运输。之前参与过一次智慧城市项目,融合了全市公交刷卡数据、出租车GPS、共享单车轨迹、甚至红绿灯相位信息,去优化公交线路和信号灯配时。你会发现,数据真的能物理上改变城市的运行。这种时候,你会觉得噼里啪啦敲的代码突然有了温度。
但!数据权力也是双刃剑。隐私问题怎么破?GDPR、数据脱敏、联邦学习……技术努力在找平衡。有一次医疗项目里,要用患者病历数据训练模型,但原始数据绝不能出医院。我们搞了一堆同态加密和差分隐私的方案,折腾得头发掉了一大把,最后勉强达到可用。啧,技术与伦理的拉扯,这大概是每个数据从业者心头的刺。
回过来说,大数据没有想象中神秘,也不是万能药。很多中小企业,数据量其实根本达不到’大数据’的门槛,硬上分布式架构反而把简单问题复杂化。我见过一家初创公司,日活才几万,非要整个K8s+Spark+Flink全家桶,运维成本比业务收入还高。何必呢?有时候,一台好服务器加上PostgreSQL就能搞定99%的需求。
所以回到最初的问题:大数据到底是什么?它不只是数据大,而是数据收集、存储、计算、分析整个范式上的颠覆。它让你能捕捉以前看不见的规律,同时也会让你掉进一堆以前没有的坑。和我吵过架的那个实习生,现在终于明白了——Excel滚不动的时候,才是故事的开始。