 我问答网
我问答网说真的,我第一次看见AI生成的手——差点把咖啡喷屏幕上。六根手指?还扭曲得像外星生物。你猜怎么着,它画脸的时候倒是挺像那么回事,眼睛鼻子挑不出大毛病。可一到手,完了。
对吧,这感觉就像一位能默写整本《红楼梦》的才子,突然不会写自己的名字。荒谬。
但这不是魔法失败,是数学、数据和生物学的连环车祸。我来拆解一下,这背后那些让人哭笑不得的原因。
手,太 TM 复杂了
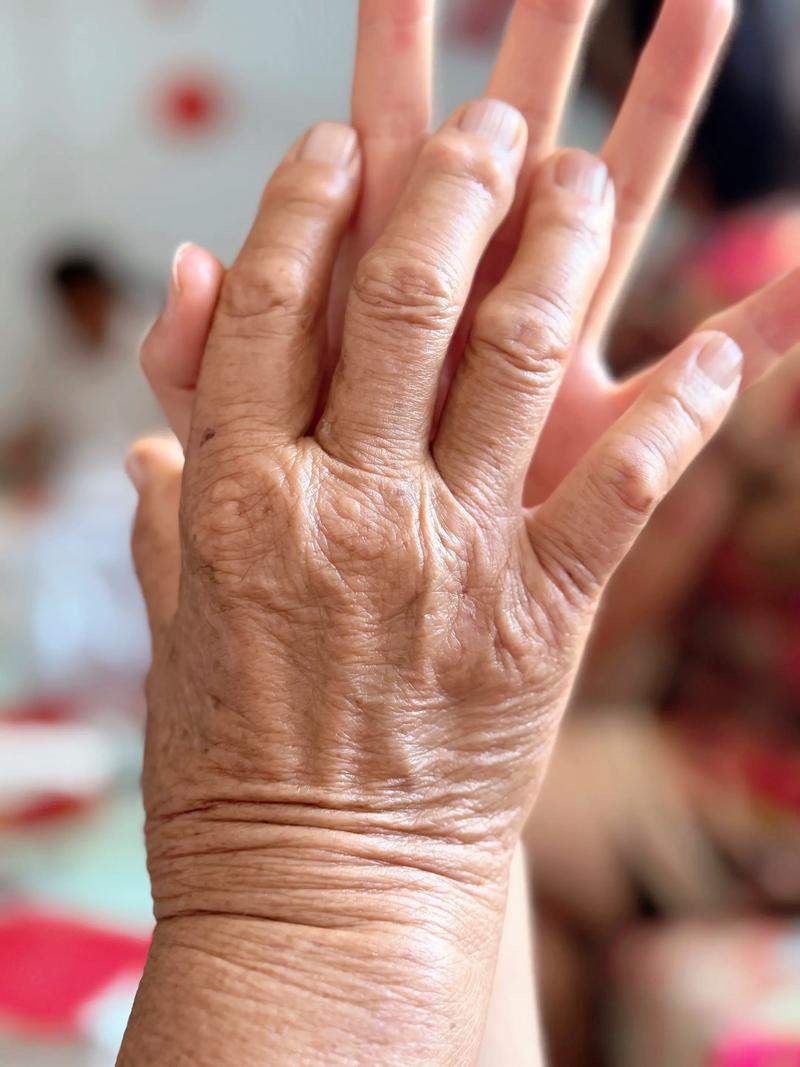
人手有多少个关节?14个指节,一堆小骨头,能做出无数种姿势。握拳、比耶、兰花指… AI根本搞不清这些结构怎么连接。它不像我们,咱们靠肉身理解空间,它只是看了一堆像素。像素懂什么三维?瞎猜呗。猜多了就猜出六根来。
而且,数据集里手的标注——一塌糊涂。你想想,图片里手经常被遮挡、模糊,或者只是画面的一小部分。训练AI的人呢,又懒得一张张仔细标出手指位置——是懒吧?还是经费不够?总之模型学了个半吊子。
💡 一个冷知识:有些研究专门给手部建模,但大部分通用模型没这耐心。它们把“画手”和“画脸”当成差不多的任务。脸有对称性,手?每根手指独立又关联,还老爱叠在一起。
扩散模型的锅
现在主流的AI绘画——比如Stable Diffusion、DALL·E——用的是扩散模型。简单说,就是先给一张图加噪点,再加,直到全成马赛克,然后让AI反过来,一步步去噪,重构出图像。这过程像什么呢?就像眯着眼看一团雾,慢慢脑补细节。
问题就在这儿。脑补的时候,它依赖训练时见过的模式。见过的手,姿势千奇百怪,但手指数量——按理说该是五根吧?呵呵,数据里却有各种奇葩:有握着东西只露出四根的,有重叠像六根的,有漫画里夸张成八爪鱼似的。AI就学坏了。它记住的“手”这个概念,本身就包含了异常。
更重要的是,扩散过程对高频细节不敏感。手指那么细,纹理又复杂,去噪初期很容易丢失结构,后期再补就成了瞎拼凑。你去看它生成过程的中间步骤,手部经常是糊成一团的,最后几步才突然冒出来。这时候,多一根少一根都是“合理”的,因为模型只追求整体看起来像,不保证解剖学正确。
脸就不一样了——眼睛鼻子嘴巴,位置固定,对称,训练数据又多。AI画脸就像考试背熟了题型,手?那是附加题,还超纲。
人类的“恐怖谷”效应
为什么我们对手指错误特别敏感?因为我们是人类。脑子里自带了“手部识别器”。你看到五根手指,哪怕比例不对,也OK。但六根——立刻警觉。这跟恐怖谷一个道理:一点偏离,好感变恐惧。AI画的六指,往往还带着奇怪的弯曲,像骨折过。我见过一张图,手指头比手掌还长… 哎,半夜看到能吓醒。
说个有意思的。有些AI艺术家故意利用这个bug,创作超现实主义作品。多指、融合、异形,突然就变成了风格。缺点反而成了签名。但这改变不了事实:绝大多数人想要的只是正常的手。
还有一点很搞笑,AI画脚也经常出问题,但大家不太在意。为啥?因为我们不习惯盯着别人的脚看。手可是社交工具,一眼就扫到了。

数据集的偏见与缺失
训练AI的图片库,比如LAION,是从网上爬的。网上啥最多?自拍、风景、产品图。这些里面,手要么没有,要么很小,要么在比“V”字——永远的剪刀手。你想想,AI学到的“手”多数时候就是V字手势。那它当然以为手指生来就是为了比耶,而且两根手指并那么紧,这不就是合并成一根了嘛?下次又分开,突然就多一根。
另外,很少有人专门拍手的特写。即使有,也是医学图谱或者特定手势。数据多样性不足,导致模型对非典型角度、肤色、年龄的手都很陌生。亚洲人习惯的比心手势,西方数据集里就少——AI画出来可能变成一坨。
标注也坑。以前数据标注外包,成本低质量差。给张照片,要求框出手部,但手指边缘模糊,标注员可能直接一个矩形框过去,有时候把旁边的东西也框进去。AI一看:哦,手指可以连接一支笔,那手指本身也可以分叉吧?
❗ 怎么办?现在很多改进方法:用专门的姿态估计模型先识别手部关键点,再引导生成;或者干脆在生成后再用修复模型把手重新画一遍。但这些都是打补丁。
说实话,要彻底解决,可能需要让AI真正理解三维结构,而不只是像素映射。这又牵扯到计算机视觉的老大难问题——从二维推断三维。NeRF、3D生成或许能帮上忙,但路还长。
乐观点?

最近Midjourney V6和SDXL已经把手指拍得好多了。有时还是翻车,但概率在降。毕竟大家都在往模型里塞更高质量的数据,甚至用合成数据专门训手。Google的Parti模型据说手部正确率大幅提升。但还是那句话——只要AI在“想象”而不是“计算”,错误就永远可能。就像你做梦,梦里手变成钳子,醒来觉得好笑。AI一直活在梦里。
不过这样也好。每次看到六根手指,我们就知道——这还是人工智能,不是真的人。带着点缺陷,反倒可爱。对吧?