 我问答网
我问答网问:大数据是不是就是数据特别多?我硬盘里存了2TB的电影算不算大数据?
答:哈哈哈哈,这个问题每次都能戳中我的笑点。说实话,我第一次听到“大数据”的时候也这么以为——数据大嘛,不就是磁盘塞爆那种。但后来被现实啪啪打脸。你那2TB电影,撑死算“死数据”,离大数据差了十万八千里。就像你不能把一仓鼠笼子叫动物园,对吧?
大数据的关键词根本不是“大”,而是……怎么说呢,一种让你没法用Excel打开的绝望感。
——你试过用Excel打开一个1GB的CSV文件吗?我试过。电脑直接把鼠标箭头变成了旋转风车,然后我就悟了。
好了,不扯淡。正经聊聊这个被字面意思玩坏的概念。
“大”在体量,但更在速度、多样和真假难辨
业界有个经典4V定义(现在都扩展到5V、7V了),但我觉得用生活例子讲更带劲儿。Volume(体量)当然是最基础的——但多少算大?十年前1TB就很吓人了,现在?呵呵,沃尔玛每小时处理的交易数据量是2.5PB。2.5PB什么概念?就是如果你用普通DVD装这些数据,摞起来有埃菲尔铁塔那么高。但光体量够也不配叫大数据,因为你那2TB电影躺那儿纹丝不动,毫无价值。
第二个V是Velocity(速度)。数据流,懂吗?像自来水一样哗哗的。比如抖音的实时推荐——你刚给一个小姐姐点了个赞,下一秒就给你推同款小姐姐。这不是因为它偷偷读了你的心,而是你点赞这个动作在毫秒级就被收进推荐引擎里搅了一圈。你要是攒一个月再分析,人家小姐姐都生二胎了,还有你啥事儿?
第三个Variety(多样性),这可是折磨死程序员的地方。你以为数据就是表格里整整齐齐的数字?醒醒吧。现在的数据包括:你发的每句语音(转文字再分析),你拍的照片(识别出里面有没有猫),你上班的GPS轨迹,你刷脸支付的3D面部点云…… 这些非结构化数据占了如今数据总量的80%以上。传统数据库碰到它们直接躺平。所以大数据的核心能力之一,就是能把垃圾山一样的杂乱信息,捋巴捋巴变成有用的东西。
还有一个很少人提的Veracity(真实性)——你咋知道你收集的数据不是一堆脏东西?传感器坏了啦,用户乱填问卷啦,爬虫爬下来一堆广告…… 拉里头常有的事。所以数据清洗往往占了一个大数据项目60%以上的时间,洗到怀疑人生。
所以现在明白了吧?你硬盘里那些电影,既没速度,又没多样性(全是MP4),而且真假不用辨——它就是电影,没一个像素是脏数据。所以,对不起,它真不叫大数据。
“多”是门槛,但技术上不去就是灾难
很多人说,那我把公司所有Excel表、服务器日志、监控视频都堆一起,不就自然成大数据了?天真!我给你画个重点:大数据的核心在于处理能力和价值挖掘,而不是囤积。就像你家堆满破烂不叫博物馆,得有人能把破烂里的青铜器挑出来、修复、讲出故事,那才行。
技术上,这涉及到两个层面:存储和计算。传统的关系型数据库,比如MySQL,处理几十亿条记录就开始喘了。而大数据体系用分布式文件系统(比如Hadoop的HDFS),把数据切成小块撒到几百台廉价机器上,每台机器只算自己那一小块,最后汇总。这就是所谓的“分而治之”思想。然后计算框架比如Spark,可以直接在内存里倒腾数据,比早期MapReduce快几十倍。还有实时流处理Flink,数据一条条进来马上算,延迟低到亚秒级。
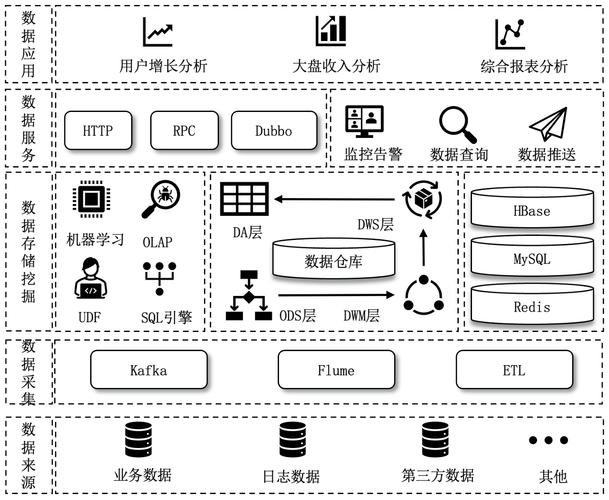
你要是没这些家伙事儿,光存着海量数据,那就像一个囤积症患者——每天看着满屋子杂物焦虑,却死活找不到去年的纳税单。而且别忘了成本:存储便宜了,但成千上万台机器的电费和降温费呢?谷歌在芬兰建数据中心有一部分原因就是那里气温低、冷却成本省一大截。所以大数据的背后,是一整套烧钱的技术设施和算法人才。
大数据的真正魔法:从“是什么”到“为什么”再到“会怎样”
最让我兴奋的其实不是技术,而是大数据分析带来的思维转变。小数据时代我们习惯“抽样”:比如街头发200份问卷,用统计工具推断所有人。但大数据能做到全量分析——就是拿所有在册用户的行为来算,没有采样误差。Netflix拍《纸牌屋》之前,分析了全站用户的观看习惯:喜欢大卫·芬奇的不行,凯文·史派西的片子点击率高,而且老版《纸牌屋》有很多人回放……于是他们砸钱定了。结果大爆。这种决策,搁以前全靠大腕儿拍脑袋,现在靠数据拍胸脯。
但这还不是终极形态。大数据三大应用方向:描述性分析(告诉你发生了什么)、预测性分析(告诉你可能发生什么)、指导性分析(告诉你该怎么做)。天气预报是描述性的;股票涨跌概率是预测性的;而自动驾驶根据路况实时调整方向盘角度,就是指导性的。 未来商业竞争,其实就是比拼谁能最快从“描述”爬到“指导”。
不过话说回来,数据也经常骗人。有一个经典例子:大数据显示,冰淇淋销量上升时溺水人数增多。难道冰淇淋吃多了会把人淹死?显然不是,因为这两者都被一个隐藏变量“天气热”推高。所以没有领域知识的纯数据挖掘,有时蠢得像用菜刀做手术。
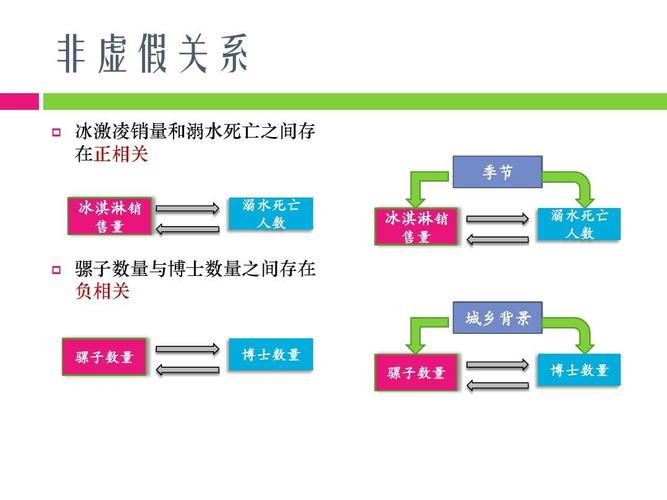
这就是为啥现在不光要数据科学家,还需要懂业务的数据翻译官。不然老板一看报表:“啥?我们最赚钱的客户是26岁养猫的单身男性?快,营销给我对准他们打!”——结果一细看,哦,样本量只有8个人,其中7个是公司内部测试账号。
你的数据,谁的生意?
聊大数据绝对不能绕过隐私。说实话,这事儿让我又爱又恨。爱的是,比如大城市的交通大数据可以实时调整红绿灯,让我上班少堵20分钟。恨的是,我昨天刚在微信里跟朋友说想去冰岛,今天打开淘宝就给我推加拿大鹅羽绒服。精准得让人毛骨悚然。
技术上,通过IMEI、IDFA、Cookie等等,各个平台早就把你的设备指纹画得像清明上河图一样精细。你每天走过哪条街、深夜刷什么内容、外卖喜欢哪家店……所有这些数据在程序化广告交易平台上被切成“你这个人”的标签,实时拍卖。RTB(实时竞价)系统能在你打开一个网页的100毫秒内发起广告位竞拍,并推送“最适合你”的广告。刺激不刺激?
现在法规在追,GDPR、个人信息保护法,都要求“最小必要+知情同意”。但实际落地呢?那些隐私弹窗,你点“同意”是因为真看完了条款,还是只想赶紧关掉它?反正我属于后者。
所以大数据有个伦理悖论:个性化服务需要更多数据,更多数据意味着更少隐私。这平衡怎么找,真不是技术问题,是人性博弈。
最后总结一下吧(虽然我不爱总结,但话总得收个尾)。大数据早不是那个“存放很多数据”的傻大个了,它是一个生态系统,融合了分布式计算、机器学习、物联网和商业智能。普通人能做的,就是稍微明白自己的数据在哪儿被用着,别傻傻的;想入行的小白,别被“大数据”三个字吓到,可以先从SQL和Python入手,再啃Spark;而企业们,别光买Hadoop集群摆着看,得有具体业务问题去驱动。
至于未来?我赌两个趋势:一是数据网格(Data Mesh),打破中心化数据湖,让业务部门自己管自己的数据然后相互服务;二是AI和大数据的更进一步结合——不是“用大数据训练AI”那么简单,而是AI帮忙自动治理大数据质量、自动发现数据里的隐藏价值链。也许哪天,老板直接对着空气喊:“帮我看看这个月为啥复购率掉了”,AI助手就能自己调数据、出图表、给建议……嗯,想想还挺带劲的。
行了,再写就真成裹脚布了。最后扔个问题给你:你觉得在你的生活中,哪一刻被大数据“击中”过?评论区唠唠。