 我问答网
我问答网啊,这个问题问到点子上了。说实话,第一次看到Midjourney画出来的图,我也惊呆了——这真是机器画的?细节、光影、构图……比我这画了十年画的人还强。然后我较上劲了,非得搞明白它怎么做到的。
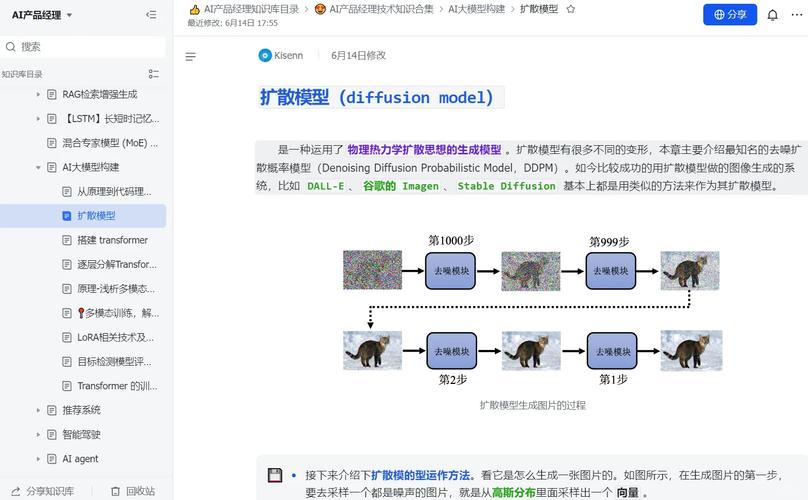
其实,核心思路特简单:从一团噪声里慢慢‘去噪’。想象一下,你拿一张老电视的雪花屏,盯久了是不是感觉能看出个脸?AI就是把这个过程反着来——它先给你看纯随机噪点,然后一步一步地清除,直到浮现出清晰的画面。
这玩意儿叫扩散模型。它训练的时候,先给一张真实图片,一层层地往上糊噪声,直到完全变成雪花,同时让它学会每一步是怎么糊的。然后推理时,就倒过来:从随机噪声开始,根据你给的文字提示,把噪声一点一点揭掉,露出底下的东西。每一步都挺微妙,得有个很强的网络预测该去掉什么噪点。
不过,等等,文字提示怎么控制画面?这才是神来之笔。模型把文字编码成一串向量,像个摇杆一样,在去噪的时候不断调整方向,让结果偏向你描述的那个样子。比如你说‘一只穿太空服的柴犬在月球上跳舞’,向量就把狗、月球、太空服这些概念搅合到一起,生成一个混合的‘概念方向’,然后去噪过程就沿着那个方向走。
当然,没那么简单。早期模型画人手总是六根指头,眼睛歪斜,因为训练数据里人像各种角度,模型很难学会手部结构的精确约束。后来改进的架构(像潜空间扩散)和更大的数据量才慢慢解决。不得不说,这过程挺像人类学画画——先临摹,再理解结构,最后创作。只不过AI临摹了几十亿张。
从一团乱麻到清晰图像,中间藏着什么?
你可能会想,这去噪听着简单,但怎么保证去掉的是噪声而不是有用信息?核心在于训练时加了条件。模型不是盲目地擦除,而是学习‘在给定当前噪声图和文字提示下,真实图片应该是什么样’,然后估计一个方向。每一步都小心翼翼,只变动一点点。通常要重复50到1000次,所以生成一张图挺费显卡的。
我跑过Stable Diffusion,用家里的游戏显卡,生成一张512×512的图大概20秒——那风扇转得跟起飞似的。还能怎么加速?后来有好多蒸馏版模型,把步骤压到4步甚至1步,画质会下降,但够用。科技真卷啊。

喂,那文字呢?咋判断是不是AI写的?

说完图,聊聊字。其实原理异曲同工。现在的大语言模型也是预测下一个token,有点像去噪的反过程?哈,不是,它更像是在一串语义向量里找最合理的延续。你给个开头,它续写,续得特顺溜,但经常胡说八道——我们叫幻觉。
怎么判断一段东西是AI写的?核心看‘信息熵’。AI生成的文字往往过于平滑,词汇分布很均匀,没有真人那种突然短路、重复口头禅、或者神来一笔的跳脱。有个工具叫GPTZero,专测这个。不过道高一尺魔高一丈,现在也有人用反向提示,让AI模仿人类的不完美……这世界太魔幻了。
话说回来,回到开头的图,现在AI甚至能生成短视频,Sora那类,本质上还是扩散模型玩到了极致——在潜空间里联合去噪时间和空间。未来可能你就是说句话,整部电影出来了。身为内容创作者,我既兴奋又有点害怕。但不管怎样,了解它的原理,至少不会觉得是魔法了。它就是个疯狂的统计学工具,对吧?只不过这工具开始有点像创造力了……细思极恐。