 我问答网
我问答网昨天又被朋友拽着问:“那啥AI绘画,咋就能凭空生出图来呢?它是不是偷偷从网上抄的?” 我…… 叹了口气,好吧,今天一口气给你唠明白。说实话,我第一次看到Midjourney出图的时候,也惊呆了——这玩意儿,有点东西。但你要是真了解背后的原理,会发现它既不神秘,也不可怕,就是数学和工程揉出来的一团面。
它其实是个“去噪”高手
你想啊,一张图,本质上就是一堆像素点,对吧?每个点有颜色。你可以把一张照片逐渐加入噪声,直到它变成纯雪花。反过来,能不能从雪花一点一点恢复出照片?扩散模型就这么干的。训练时,它拿着清晰的图,一步步加噪声,让图像越来越糊,最终变成一片混沌。然后再让它学习从混沌中逐步去掉噪声,回到清晰图。反复磨炼几百万次,它就学会了“猜出”模糊中可能隐藏的真实细节。
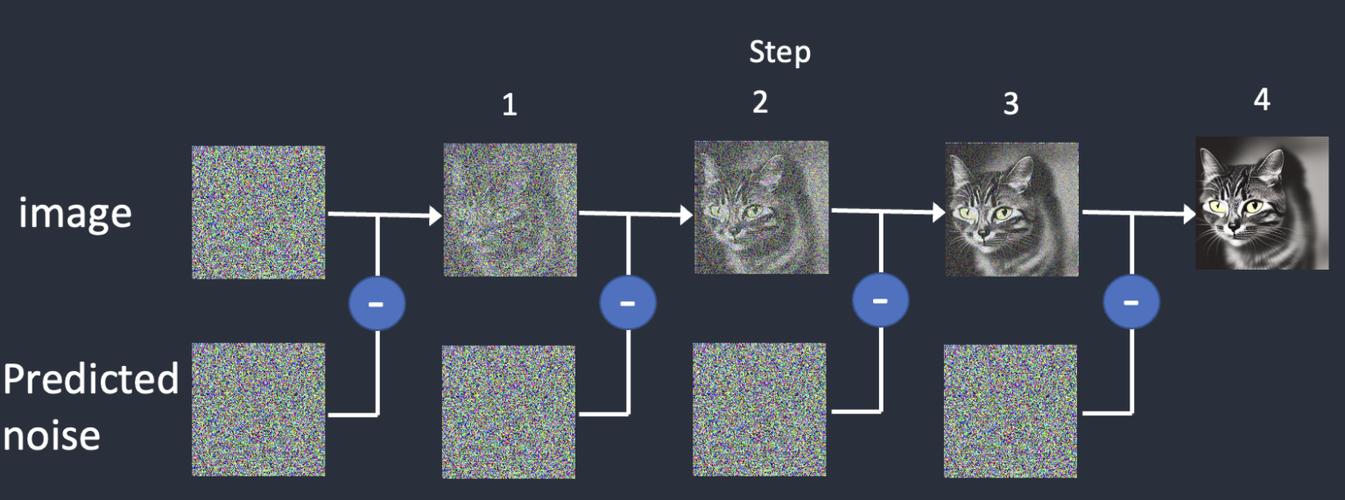
推理出图时,你给它一个纯粹随机的噪声图,它就开始猜:“这一步,应该去掉哪些噪点,能让图像更像真实世界的东西?” 但光这样,它只会生成任意的真实图像,比如随便一个风景或一只猫。怎么让它听话,画出你要的“穿宇航服的柴犬”呢?这时候就需要一个指挥官——文本条件。
文字和图像之间的“翻译官”
这里就要提到一个巨牛的东西——CLIP模型(OpenAI家的)。它就像个超级翻译官,把文字和图像塞进同一个理解空间。你输入一句话,它能算出这句话的向量;看到一张图,也能算出图的向量。然后CLIP被训练得让匹配的图文向量距离近,不匹配的距离远。把这套能力安到绘画模型上,在去噪的每一步,都会计算当前图片的CLIP向量和你文字描述的CLIP向量之间的差距,然后引导去噪方向,缩小这个差距。这么一来,生成的图就一点点朝着你描述的样子靠拢了。
不过,有时候它也会犯傻。我上周让它画“一个没有大象的房间”,你猜怎么着?它给我整了只大象出来!——唉,对“没有”这个词的理解,还是差点意思。😂 但话说回来,大方向已经抓得很准了,对吧?你让它画“赛博朋克雨夜街头”,那霓虹灯反射在湿漉漉地面的效果,绝了。
吃数据长大的“神笔马良”

模型牛不牛,全靠数据喂。这些AI绘画模型,那是真的“吃”了几十亿张图片。什么名画、照片、插画、3D渲染、甚至表情包,全吞进去。然后它就能模仿各种风格。你让它画梵高风格的咖啡馆,嚯,笔触那叫一个像,扭曲的线条,浓烈的色彩,八九不离十。但其实它并没有真正理解梵高为什么那么画,它只是在统计上找到了那些风格的视觉模式,然后重新拼凑出来。
这让我想起一个好玩的事。有一次我想生成一张“唐代诗人李白在月球上喝酒”的图。结果它给出的李白穿着宇航服,手里还拿着卷轴,背景是地球。我哭笑不得——这到底是创意呢,还是缝合怪?不过说实话,这种意外有时候反而比正儿八经的图更有趣。
但这事儿也惹过不少争议❗ 有些艺术家发现,AI生成的图跟自己的作品风格太像了,感觉被白嫖。毕竟训练数据里包含了他们的画作,而模型并没有得到授权。目前法律上还是灰色地带,以后怎么搞,谁也不知道。不过我作为一个普通用户,还是玩得挺开心的——不用学十年画画,也能把脑子里的奇怪想法变成图,爽。
别神化它,也别小看它

玩久了你会发现,AI绘画有很多搞笑的缺陷。最经典的就是画手:常常多出一两根手指,或者手指扭曲得跟外星人似的。因为手在训练数据中的形态太多变了,模型很难抓住稳定的规律。还有光影逻辑,有时候光源在左边,但某个物体的阴影却投向了左边,物理上根本不可能。字体生成更是灾难,你让它写个招牌,它能把字母画得像鬼画符。
所以啊,现阶段它更像一个超级辅助工具。设计师用它快速出草图,插画师用它找灵感,普通人用它娱乐。它不会取代真正的艺术家,因为艺术不只是图像,还有背后的思考和情感。但你要是对它有合理的期待,就会觉得——真香。
行了,今天就扯这么多。下次谁再一脸迷茫地问你AI绘画怎么回事,你就把这篇文章甩过去。记得带他多玩玩,这东西,上手比理论有意思多了。😎